What is it?
MapReduce is a programming model to simplify processing of huge data on large number of machines. This programming model was introduced in the paper published by google's Jeffrey Dean and Sanjay Ghemawat. More details at http://labs.google.com/papers/mapreduce.html.
Why?
Programmers without any experience of parallel programming and distributed systems can easily write programs to process huge data sets on large number of machines using this model.
When?
Need to process lots of data
How?
Write map, reduce functions and feed them to the MapReduce framework. The framework takes care of slicing and distributing the work to multiple machines, processing, handling failures, and giving the result back.
Since picture is a thousand words, let's see how we can take 1,000,000 text documents, look through them, and find how many times each word is used. Actually wait a minute, to make this example simple, lets do just do 2 documents. But, huge data is where this programming model shines. I borrowed this example from hadoop tutorial at http://hadoop.apache.org/common/docs/current/mapred_tutorial.html
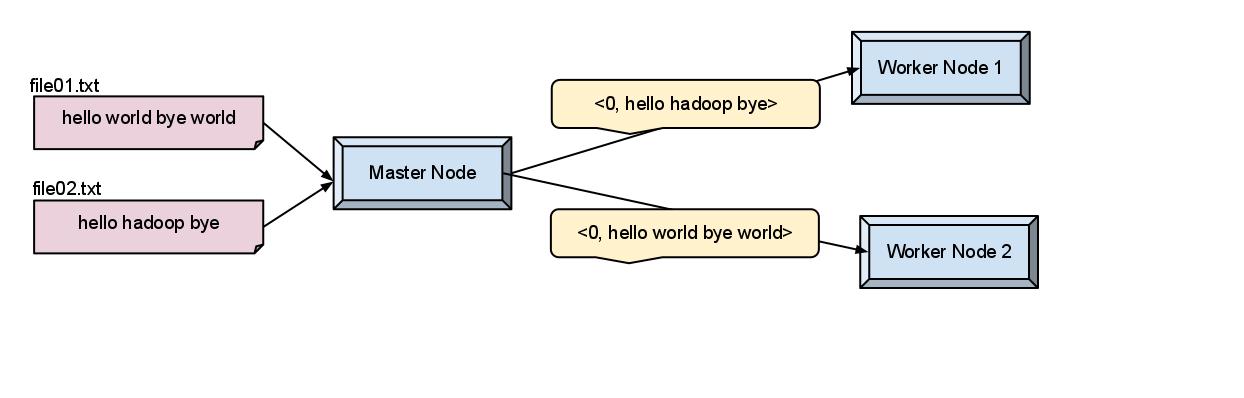
1) In the first step, we feed these two documents to the master node. Master node splits the data and sends it to worker nodes (perform map function) to process the data.

2) Now, worker nodes process the data and give the result back to the master node. Master node then collects the data from all the worker nodes, arranges them by key, and sends them to other worker nodes to perform reduce function.

3)After performing the reduce function, worker nodes give the result back to the master node. Now, the master node processes the resulting data and gives the result (which is count of all words from both documents).

When you think about huge amount of data, leveraging cluster of machines using MapReduce programming model is an efficient way to deal with it.
MapReduce is a programming model to simplify processing of huge data on large number of machines. This programming model was introduced in the paper published by google's Jeffrey Dean and Sanjay Ghemawat. More details at http://labs.google.com/papers/mapreduce.html.
Why?
Programmers without any experience of parallel programming and distributed systems can easily write programs to process huge data sets on large number of machines using this model.
When?
Need to process lots of data
How?
Write map, reduce functions and feed them to the MapReduce framework. The framework takes care of slicing and distributing the work to multiple machines, processing, handling failures, and giving the result back.
Since picture is a thousand words, let's see how we can take 1,000,000 text documents, look through them, and find how many times each word is used. Actually wait a minute, to make this example simple, lets do just do 2 documents. But, huge data is where this programming model shines. I borrowed this example from hadoop tutorial at http://hadoop.apache.org/common/docs/current/mapred_tutorial.html
1) In the first step, we feed these two documents to the master node. Master node splits the data and sends it to worker nodes (perform map function) to process the data.


When you think about huge amount of data, leveraging cluster of machines using MapReduce programming model is an efficient way to deal with it.
No comments:
Post a Comment